Introduction to R
John Little
## [1] "This document was last updated 2016-10-26"The intended audience are newbies who just wanna start playing around with with [R]. The first section below simply loads preliminary [R] packages. If you don’t need to know this now, Skip ahead to Begin - Intro to R.
0.1 Library Packages
Load all the packages for this tutorial. Strictly speaking this is a two step process: (1) install the package; (2) load the package. I’ll include the install commands for reproducibility, but you can probably skip to simply loading the packages. If any package doesn’t load, you can uncomment the “install.packages” command for that package (remove the # preceding the relevant install.packages command.) Then, rerun the relevant code-chucks.
A note about the packages. The necessary packages that make up the bulk of concepts taught in this workshop are: readr, dplyr, and ggplot2. These packages and others are all integrated into tidyverse. stringr, and stringi are for string manipulation but we won’t go into great depth as to their use. The rmarkdown package is a utility that allows me to compose this workshop and create code-chunks.
# If you do not have these packages already installed in your packages list, you can install them by uncommenting the following lines.
#
# install.packages("tidyverse")
# install.packages("stringr")
# install.packages("stringi")
# Load packages required for this workshop
require(tidyverse)
require(stringr)
require(stringi)0.2 Tidyverse / Hadleyverse
These days, much of what we try to accomplish within the data universe requires reshaping the data. The various reshaping activies occur with almost astounding frequency among datasmiths. Much of this activity has been identified as the Split-Apply-Combine Strategy1 by Hadley Wickam. To that end, Hadley Wickham has authored or coauthored many packages which augment the base-R functionality in support of more convenient data wrangling. Hadley’s efforts have been broadly adopted to the point of earning a nickname for the suite of packages: “Hadleyverse.” Recently that nickname has been formalized as tidyverse. You can read more about this in The Hitchhiker’s Guide to the Hadleverse2 by Adolfo Alvarez.
1 Begin - Intro to R
[R] is a popular programming language with embedded statistical capabilities. The [R] language is also popular as a data science toolset. If you want to read more about the origins and definitions of [R] try starting at the Wikipedia entry. Our focus in this introduction will develop your skills working in the RStudio IDE (development environment), data reshaping, generating cross tablulations, and generating rudimentary visualizations.
2 The Wow Factor
First, let’s check out a supper niffty cool visualizations accomplished in [R] with with minimal code. The example below is inspired and derived from by 5 data visualizations in 5 minutes: each in 5 lines or less of R by Sharon Machlis3
require(readr) ; require(leaflet); library(magrittr)
starbucks <- read_csv("https://opendata.socrata.com/api/views/ddym-zvjk/rows.csv")
tbl_df(starbucks) %>%
filter(State == "NC") -> starbucks
leaflet() %>%
addTiles() %>%
setView(-78.8310, 35.9867, zoom = 10) %>%
addMarkers(data = starbucks, lat = ~ Latitude, lng = ~ Longitude, popup = starbucks$Name)3 Data Structure Types
The following image, from First Steps in R (Ceballos & Cardiel)4, is a handy visualization to explain the data types available in [R].

R Data Types
The object orientation of [R] allows you to be specific, atmostic, about object characteristics. These characteristics are called Data Types or Data Structures. This level of specificity can yield sophisticated outcome but may also lead to confusion, especially with those learning R. For this workshop we’ll stick with two very common data types: Vectors & Data Frames.
3.1 Vectors and Data Frames
- Vectors are one dimensional arrays in which all values must of the same type. That is, in a vector, each element of the vector homogeneous; they must be one of the following types: Numeric, Complex, Logical, or Character
- Factors are vectors used when working with categorical variables.
- Data Frames are generalized matrices. Different columns can store different types including vectors, lists, Factors, Arrays, and Functions. You want Heterogeneity? Data frames are where that starts.
- More Data Types
tl;dr?
For now, remember you can only store one data type in a vector, but you can store multiple vectors, vectors of different data types, in a data frame. I encourage you to read more about Data Types, later. Simply put, many [R] road blocks occur when the [R] programmer misunderstands the data structure of a particular data object. On the other hand, if you’re working with statistics, this level of atomization brings critical and useful functionality.
4 Variable Assignment
Variable or object names are most commonly assigned using the <- operator but there are many equivalent assignment operators.
- Assignment Operators
<<-<-=->->>
# Assign "foo" as a three item character vector:
foo <- c("apple", "bannana", "grape") # c() is the "concatenate" function
foo ->> bar
# now recall the value of those objects by name:
foo## [1] "apple" "bannana" "grape"bar## [1] "apple" "bannana" "grape"5 Data Management
5.1 Sample data
5.1.1 Overview process
- Download the sample UnempData.csv file to a directory on your local workstation. Do this now.
- Move or upload the file to your working directory as identified by the command
getwd() - Load that data using assignments and the
read_csvfunction - Skip now to the section [R] and your file system (below)
5.1.2 Other downloading & loading techniques
Note: You don’t need to follow these steps but be aware there many ways to load data
- download a file directory to your working directory
download.file("https://ndownloader.figshare.com/files/5909145?private_link=50e77f2201ac90141e4c", "foo.csv")
- load a file via http – which you will do later in this workshop.
It’s also important to understand how [R] works with your local file system.
5.2 [R] and your file system
5.2.1 getwd()
Identify [R]’s default data directory.
getwd()## [1] "C:/Users/jrl/Documents/R/github/R-intro-and-reference/scripts"5.2.2 setwd()
- You can change the working directory using
setwd()setwd("c:/somedir/")
5.3 Construct filepath/filename variable
Practice working with your file-system environment variables and assigning those values to object names.
DIR <- getwd()
filename <- "UnempData.csv"
fullpath <- paste(DIR, "/../data/", filename, sep = '') # paste() to concatenate vectors
fullpath #display the value of fullpath in the console## [1] "C:/Users/jrl/Documents/R/github/R-intro-and-reference/scripts/../data/UnempData.csv"5.4 Where is my data?
If you upload data using any of the following methods in RStudio then you can ignore the preceding about manipulating the files-system and directory structure.
- From the Environment/History Pane (screenshot)
Environment Tab > Import Datasets
- From the Help Pane
Files Tab > Upload
- From the File menu bar
File > Open File
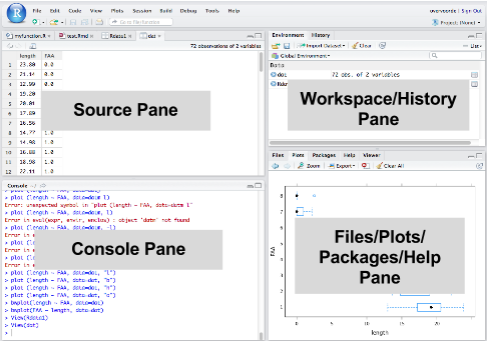{kind=link}
5.5 Load a CSV file
In this example we use the read_csv() function, part of the readr library. I recommend readr because it automatically imports character data as characters without also automatically assign those characters as factors. This is an improvement over the default “base-R” approach which automatically converts characters to factors whenever [R] thinks that’s a good idea.
# read the uploaded CSV file into a data frame.
# using the read_csv() function, part of the readr package loaded earlier
# To get help using read_csv() type the following into the console: ?read_csv [Enter]
unempdata <- read_csv(fullpath)## Parsed with column specification:
## cols(
## ID = col_integer(),
## `recode: any discrimination` = col_character(),
## `lost my job` = col_character(),
## underemployed = col_character(),
## `removed from direct contact with clients` = col_character(),
## `denied a promotion` = col_character()
## )5.6 Other data loaders
There are many other types of data you may want to load such as SAS, SPSS, Stata, Excel, Google Sheets, etc. Loading packages are available to support many methods. Some of the more common “file formats” are supported by the following packages:
- foreign - load data from SPSS, SAS, and other Statistical Analysis applications
- readxl - load Excel data
- googlesheets - load data from Google Sheets
6 Identify and Display
There are various methods of identifying the descriptive characteristics of data objects in R.
6.1 View()
Display your data in a grid style within the Source Editor pane (screenshot). The View() function is typed with an uppercase V.
View(unempdata) 6.2 class() - class of the data type
Identify the data variable characteristics of the data object.
class(unempdata)## [1] "tbl_df" "tbl" "data.frame"6.3 dim() - dimensions
Identify the dimensions of the data object.
dim(unempdata)## [1] 50 6That’s 50 rows, or observations, and six columns, or variables.
6.4 nrow() - number of rows
Identify the number of rows in the data object.
nrow(unempdata)## [1] 506.5 ncol() - number of columns
Identify the number of columns in the data object.
ncol(unempdata)## [1] 66.6 str() - Structure
Identify the structure of the data object.
str(unempdata)## Classes 'tbl_df', 'tbl' and 'data.frame': 50 obs. of 6 variables:
## $ ID : int 1 2 3 4 5 6 7 8 9 10 ...
## $ recode: any discrimination : chr "Yes" "Yes" "Yes" "Yes" ...
## $ lost my job : chr "No" "No" "No" "No" ...
## $ underemployed : chr "No" "No" "No" "No" ...
## $ removed from direct contact with clients: chr "Yes" "No" "No" "No" ...
## $ denied a promotion : chr "No" "No" "Yes" "No" ...
## - attr(*, "spec")=List of 2
## ..$ cols :List of 6
## .. ..$ ID : list()
## .. .. ..- attr(*, "class")= chr "collector_integer" "collector"
## .. ..$ recode: any discrimination : list()
## .. .. ..- attr(*, "class")= chr "collector_character" "collector"
## .. ..$ lost my job : list()
## .. .. ..- attr(*, "class")= chr "collector_character" "collector"
## .. ..$ underemployed : list()
## .. .. ..- attr(*, "class")= chr "collector_character" "collector"
## .. ..$ removed from direct contact with clients: list()
## .. .. ..- attr(*, "class")= chr "collector_character" "collector"
## .. ..$ denied a promotion : list()
## .. .. ..- attr(*, "class")= chr "collector_character" "collector"
## ..$ default: list()
## .. ..- attr(*, "class")= chr "collector_guess" "collector"
## ..- attr(*, "class")= chr "col_spec"6.7 head() - show top rows
Identify the top rows of the data object.
head(unempdata)## # A tibble: 6 x 6
## ID recode: any discrimination lost my job underemployed
## <int> <chr> <chr> <chr>
## 1 1 Yes No No
## 2 2 Yes No No
## 3 3 Yes No No
## 4 4 Yes No No
## 5 5 Yes No Yes
## 6 6 Yes No No
## # ... with 2 more variables: removed from direct contact with
## # clients <chr>, denied a promotion <chr>6.8 tail() - show last rows
Identify the bottom twenty rows of the data object
tail(unempdata, 20) # in this case, show the last 20 rows## # A tibble: 20 x 6
## ID recode: any discrimination lost my job underemployed
## <int> <chr> <chr> <chr>
## 1 31 Yes No No
## 2 32 Yes Yes No
## 3 33 Yes Not Applicable Not Applicable
## 4 34 Yes Not Applicable Not Applicable
## 5 35 Yes Not Applicable Not Applicable
## 6 36 Yes No No
## 7 37 Yes Not Applicable Not Applicable
## 8 38 Yes No Yes
## 9 39 Yes No Yes
## 10 40 Yes No Yes
## 11 41 Yes No Not Applicable
## 12 42 Yes No No
## 13 43 Yes No No
## 14 44 Yes Yes Yes
## 15 45 Yes Yes Yes
## 16 46 Yes Yes No
## 17 47 Yes No Yes
## 18 48 Yes No No
## 19 49 Yes No No
## 20 50 Yes No No
## # ... with 2 more variables: removed from direct contact with
## # clients <chr>, denied a promotion <chr>6.9 summary() - get summary statistics when available
Identify a statistical summary of the data object.
summary(unempdata)## ID recode: any discrimination lost my job
## Min. : 1.00 Length:50 Length:50
## 1st Qu.:13.25 Class :character Class :character
## Median :25.50 Mode :character Mode :character
## Mean :25.50
## 3rd Qu.:37.75
## Max. :50.00
## underemployed removed from direct contact with clients
## Length:50 Length:50
## Class :character Class :character
## Mode :character Mode :character
##
##
##
## denied a promotion
## Length:50
## Class :character
## Mode :character
##
##
## 6.10 colnames()
List all column names
colnames(unempdata)## [1] "ID"
## [2] "recode: any discrimination"
## [3] "lost my job"
## [4] "underemployed"
## [5] "removed from direct contact with clients"
## [6] "denied a promotion"6.11 rownames()
List all row names
rownames(mtcars) # NOTE: I used a different data frame, one with actual row names ;-j## [1] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710"
## [4] "Hornet 4 Drive" "Hornet Sportabout" "Valiant"
## [7] "Duster 360" "Merc 240D" "Merc 230"
## [10] "Merc 280" "Merc 280C" "Merc 450SE"
## [13] "Merc 450SL" "Merc 450SLC" "Cadillac Fleetwood"
## [16] "Lincoln Continental" "Chrysler Imperial" "Fiat 128"
## [19] "Honda Civic" "Toyota Corolla" "Toyota Corona"
## [22] "Dodge Challenger" "AMC Javelin" "Camaro Z28"
## [25] "Pontiac Firebird" "Fiat X1-9" "Porsche 914-2"
## [28] "Lotus Europa" "Ford Pantera L" "Ferrari Dino"
## [31] "Maserati Bora" "Volvo 142E"7 Data Wrangling with dplyr
dplyr is a broadly adopted package which supports data manipulation (aka data cleaning, data wrangling, data janitor, data engineering, etc.)
7.1 tbl_df
tbl_df() provides a convenient summary of the characteristics of a data frame object. This function has similarity with str() and many of the functions covered in the preceding section.
tbl_df(unempdata)## # A tibble: 50 x 6
## ID recode: any discrimination lost my job underemployed
## <int> <chr> <chr> <chr>
## 1 1 Yes No No
## 2 2 Yes No No
## 3 3 Yes No No
## 4 4 Yes No No
## 5 5 Yes No Yes
## 6 6 Yes No No
## 7 7 Yes Yes Not Applicable
## 8 8 Yes Not Applicable Not Applicable
## 9 9 Yes No Not Applicable
## 10 10 Yes No No
## # ... with 40 more rows, and 2 more variables: removed from direct contact
## # with clients <chr>, denied a promotion <chr>7.2 rename() - edit column names
In the example below, use the colnames() function before and after the rename() function so you can see the effect.
colnames(unempdata) # identify the existing column names## [1] "ID"
## [2] "recode: any discrimination"
## [3] "lost my job"
## [4] "underemployed"
## [5] "removed from direct contact with clients"
## [6] "denied a promotion"unempdata <- rename(unempdata, discriminate = `recode: any discrimination`, no_job = `lost my job`, no_clients = `removed from direct contact with clients`, promotion = `denied a promotion`) # rename column names
colnames(unempdata) # Proof that the names where changed by using the reassignment operator## [1] "ID" "discriminate" "no_job" "underemployed"
## [5] "no_clients" "promotion"7.3 recode()
- recode to change the data values
- recode for the NA Characteristics
- Replace “Not Applicable” with the “NA” chacter )
unempdata$no_job <- recode(unempdata$no_job, No = "FALSE", Yes = "TRUE", "Not Applicable" = NA_character_)7.4 str_pad() - String Padding
Leading or Padding zeros
unempdata$ID <- str_pad(unempdata$ID, 3, pad = "0")7.5 as.logical()
Change to vector data type to logical vector (i.e. TRUE / FALSE)
class(unempdata$no_job)## [1] "character"unempdata$no_job <- as.logical(unempdata$no_job)
tbl_df(unempdata)## # A tibble: 50 x 6
## ID discriminate no_job underemployed no_clients promotion
## <chr> <chr> <lgl> <chr> <chr> <chr>
## 1 001 Yes FALSE No Yes No
## 2 002 Yes FALSE No No No
## 3 003 Yes FALSE No No Yes
## 4 004 Yes FALSE No No No
## 5 005 Yes FALSE Yes No No
## 6 006 Yes FALSE No No No
## 7 007 Yes TRUE Not Applicable Yes No
## 8 008 Yes NA Not Applicable Not Applicable Not Applicable
## 9 009 Yes FALSE Not Applicable Not Applicable Not Applicable
## 10 010 Yes FALSE No No No
## # ... with 40 more rowssummary(unempdata)## ID discriminate no_job underemployed
## Length:50 Length:50 Mode :logical Length:50
## Class :character Class :character FALSE:31 Class :character
## Mode :character Mode :character TRUE :8 Mode :character
## NA's :11
## no_clients promotion
## Length:50 Length:50
## Class :character Class :character
## Mode :character Mode :character
## 7.6 FILTER - subset rows
filter() can take multiple arguments (e.g. cyl >= 4, cyl <= 6)
Note: We’re using a new data set
data("mtcars") # load the onboard mtcars dataset, part of base-R
?mtcars # get more information about this dataset in the help pane## starting httpd help server ...## donetbl_df(mtcars)## # A tibble: 32 x 11
## mpg cyl disp hp drat wt qsec vs am gear carb
## * <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## 2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## 3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## 4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## 5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## 6 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## 7 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
## 8 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## 9 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## 10 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
## # ... with 22 more rows7.6.1 filter()
Make a custom data frame called “four.six” that consists of only the four and six cylinder cars
four.six <- filter(mtcars, mtcars$cyl <8) #filter out 8 cylinder cars and make a new data.frame "four.six"
tbl_df(four.six) #Alas! now rownames## # A tibble: 18 x 11
## mpg cyl disp hp drat wt qsec vs am gear carb
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## 2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## 3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## 4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## 5 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## 6 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## 7 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## 8 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
## 9 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
## 10 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
## 11 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
## 12 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
## 13 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
## 14 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
## 15 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
## 16 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
## 17 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
## 18 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 27.7 Putting it together
- gather the row names values into a vector and move that data into its own column
- rename the new column: “makeModel”
select()only a few specific columns for my data framefilter()out the 8 cylinder vehicles with selectmutate()- add a column by calculating new custom values for a new variable
four.six <- mutate(mtcars, rownames(mtcars)) #add the row names as a separate column
four.six <- rename(four.six, makeModel = `rownames(mtcars)`) #rename the added, auto-named column
four.six <- select(four.six, makeModel, mpg:wt) #select only the columns wanted
four.six <- filter(four.six, cyl >= 4, cyl <=6) # filter rows
four.six <- mutate(four.six,
wtdisp = disp / wt
) # augment data
tbl_df(four.six)## # A tibble: 18 x 8
## makeModel mpg cyl disp hp drat wt wtdisp
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Mazda RX4 21.0 6 160.0 110 3.90 2.620 61.06870
## 2 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 55.65217
## 3 Datsun 710 22.8 4 108.0 93 3.85 2.320 46.55172
## 4 Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 80.24883
## 5 Valiant 18.1 6 225.0 105 2.76 3.460 65.02890
## 6 Merc 240D 24.4 4 146.7 62 3.69 3.190 45.98746
## 7 Merc 230 22.8 4 140.8 95 3.92 3.150 44.69841
## 8 Merc 280 19.2 6 167.6 123 3.92 3.440 48.72093
## 9 Merc 280C 17.8 6 167.6 123 3.92 3.440 48.72093
## 10 Fiat 128 32.4 4 78.7 66 4.08 2.200 35.77273
## 11 Honda Civic 30.4 4 75.7 52 4.93 1.615 46.87307
## 12 Toyota Corolla 33.9 4 71.1 65 4.22 1.835 38.74659
## 13 Toyota Corona 21.5 4 120.1 97 3.70 2.465 48.72211
## 14 Fiat X1-9 27.3 4 79.0 66 4.08 1.935 40.82687
## 15 Porsche 914-2 26.0 4 120.3 91 4.43 2.140 56.21495
## 16 Lotus Europa 30.4 4 95.1 113 3.77 1.513 62.85525
## 17 Ferrari Dino 19.7 6 145.0 175 3.62 2.770 52.34657
## 18 Volvo 142E 21.4 4 121.0 109 4.11 2.780 43.525187.7.1 Magrittr - Command pipes
Some folks say there’s a better way to put it all together, that’s using the magrittr package
mtcars %>%
mutate(rownames(mtcars)) %>%
rename(makeModel = `rownames(mtcars)`) %>%
filter(cyl >= 4, cyl <=6) %>%
select(makeModel, mpg:wt) %>%
mutate(dispWt = disp / wt) %>%
arrange(cyl, desc(mpg), hp, wt)-> grtr.46
grtr.46## makeModel mpg cyl disp hp drat wt dispWt
## 1 Toyota Corolla 33.9 4 71.1 65 4.22 1.835 38.74659
## 2 Fiat 128 32.4 4 78.7 66 4.08 2.200 35.77273
## 3 Honda Civic 30.4 4 75.7 52 4.93 1.615 46.87307
## 4 Lotus Europa 30.4 4 95.1 113 3.77 1.513 62.85525
## 5 Fiat X1-9 27.3 4 79.0 66 4.08 1.935 40.82687
## 6 Porsche 914-2 26.0 4 120.3 91 4.43 2.140 56.21495
## 7 Merc 240D 24.4 4 146.7 62 3.69 3.190 45.98746
## 8 Datsun 710 22.8 4 108.0 93 3.85 2.320 46.55172
## 9 Merc 230 22.8 4 140.8 95 3.92 3.150 44.69841
## 10 Toyota Corona 21.5 4 120.1 97 3.70 2.465 48.72211
## 11 Volvo 142E 21.4 4 121.0 109 4.11 2.780 43.52518
## 12 Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 80.24883
## 13 Mazda RX4 21.0 6 160.0 110 3.90 2.620 61.06870
## 14 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 55.65217
## 15 Ferrari Dino 19.7 6 145.0 175 3.62 2.770 52.34657
## 16 Merc 280 19.2 6 167.6 123 3.92 3.440 48.72093
## 17 Valiant 18.1 6 225.0 105 2.76 3.460 65.02890
## 18 Merc 280C 17.8 6 167.6 123 3.92 3.440 48.720937.8 Arrange the data output
arrange() the data in a custom order in a data frame display
arrange(four.six, cyl, desc(mpg), desc(hp), wt, wtdisp)## makeModel mpg cyl disp hp drat wt wtdisp
## 1 Toyota Corolla 33.9 4 71.1 65 4.22 1.835 38.74659
## 2 Fiat 128 32.4 4 78.7 66 4.08 2.200 35.77273
## 3 Lotus Europa 30.4 4 95.1 113 3.77 1.513 62.85525
## 4 Honda Civic 30.4 4 75.7 52 4.93 1.615 46.87307
## 5 Fiat X1-9 27.3 4 79.0 66 4.08 1.935 40.82687
## 6 Porsche 914-2 26.0 4 120.3 91 4.43 2.140 56.21495
## 7 Merc 240D 24.4 4 146.7 62 3.69 3.190 45.98746
## 8 Merc 230 22.8 4 140.8 95 3.92 3.150 44.69841
## 9 Datsun 710 22.8 4 108.0 93 3.85 2.320 46.55172
## 10 Toyota Corona 21.5 4 120.1 97 3.70 2.465 48.72211
## 11 Volvo 142E 21.4 4 121.0 109 4.11 2.780 43.52518
## 12 Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 80.24883
## 13 Mazda RX4 21.0 6 160.0 110 3.90 2.620 61.06870
## 14 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 55.65217
## 15 Ferrari Dino 19.7 6 145.0 175 3.62 2.770 52.34657
## 16 Merc 280 19.2 6 167.6 123 3.92 3.440 48.72093
## 17 Valiant 18.1 6 225.0 105 2.76 3.460 65.02890
## 18 Merc 280C 17.8 6 167.6 123 3.92 3.440 48.720937.9 Regex & Capture Groups
Now it’s time for some advanced string manipulation to set the data up for Visualization in the next section. String manipulation is pretty common in the world of datasmithing but it’s not so easy in [R]. Of course some packages exist to help. We won’t go into too much detail right now but the following two examples enble pattern matching and capture groups which are fundamentals of regular expressions. However, I’ll gloss over this for now as the inspired focus of [R] is statistics.
- take the first word (make of automobile) from the makeModel column and put it in its own column
# library(stringr)
four.six$make <- word(four.six$makeModel, 1)
four.six$make # dipsplay the maker## [1] "Mazda" "Mazda" "Datsun" "Hornet" "Valiant" "Merc" "Merc"
## [8] "Merc" "Merc" "Fiat" "Honda" "Toyota" "Toyota" "Fiat"
## [15] "Porsche" "Lotus" "Ferrari" "Volvo"# ignore this next line although it may come in handy to some.
# str_extract(four.six$makeModel, "\\w+\\s(.*)")- Take all the words following the first word (model) and put that string in it’s own column
# library(stringi)
four.six$model <- stri_match_last_regex(four.six$makeModel, "\\w+\\s(.*)", cg_missing = "")[,2]
four.six$model #display the model## [1] "RX4" "RX4 Wag" "710" "4 Drive" "" "240D" "230"
## [8] "280" "280C" "128" "Civic" "Corolla" "Corona" "X1-9"
## [15] "914-2" "Europa" "Dino" "142E"# ignore this next two lines although it may come in handy to some.
# stri_match_all_regex(four.six$makeModel, "\\w+\\s(.*)")[[1]][2]8 Tables - Cross Tabulations
Building cross-tabulated (Markham)5 tables
Note: New data set and examples from an R Tutorial by (Kelly Black)6
8.1 unique() - variable values
unique() is contextually related to table() in that it reveals the unique values within a variable. To demonstrate the table() function, let’s use an example and example data made available from Kelly Black’s [R] Tutorial.
# R Tutorial by Kelly Black is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License (2015).
# http://www.cyclismo.org/tutorial/R/tables.html#graphical-views-of-tables
smokerdata <- read_csv("http://www.cyclismo.org/tutorial/R/_static/smoker.csv")## Parsed with column specification:
## cols(
## Smoke = col_character(),
## SES = col_character()
## )tbl_df(smokerdata) # Note the structure of the data## # A tibble: 356 x 2
## Smoke SES
## <chr> <chr>
## 1 former High
## 2 former High
## 3 former High
## 4 former High
## 5 former High
## 6 former High
## 7 former High
## 8 former High
## 9 former High
## 10 former High
## # ... with 346 more rowsunique(smokerdata$Smoke) # Note the unique values for the Smoke variable## [1] "former" "current" "never"unique(smokerdata$SES) # Note the unique values for the SES variable## [1] "High" "Middle" "Low"8.2 table()
As noted above, table() is similar to unique() except that it not only reveals the unique variables but it also calculates the frequency of those variables.
table(smokerdata) # Create a cross tablulation## SES
## Smoke High Low Middle
## current 51 43 22
## former 92 28 21
## never 68 22 9table(smokerdata$Smoke) # Gather frequency data for a single variable##
## current former never
## 116 141 998.3 count()
# This one is cool...
tbl_df(four.six) %>%
count(hp)## # A tibble: 14 x 2
## hp n
## <dbl> <int>
## 1 52 1
## 2 62 1
## 3 65 1
## 4 66 2
## 5 91 1
## 6 93 1
## 7 95 1
## 8 97 1
## 9 105 1
## 10 109 1
## 11 110 3
## 12 113 1
## 13 123 2
## 14 175 19 Visualizations
9.1 Basic Vis
When in the data exploratory phase, you can quickly generate very basic visualizations with minmal effort. Your visualiations then appear in the Viewer Pane. While you may not want to share these visualizations, the simplicity of generating quick histograms can help you understand your data as you begin thinking about your analysis.
Type these commans into your console.
To generate
- Histogram:
hist(mtcars$mpg) - Scatterplot:
plot(mtcars$wt, mtcars$mpg) - Barplot:
barplot(table(mtcars$cyl))
9.1.1 plot() - Scatter Plot
plot() will generate a scatter plot. To demonstrate this I’ll introduce a new dataset, Egar Anderson’s Iris Data. The data contains the measurements in centimeters of various flowers: variable sepal and petal measurements in length and width for 50 flowers from each of 3 species of iris. You can find more information about this dataset by typing ?iris in the console pane. The scatter plot example comes from Peter Cock’s guide to plotting in [R]7 which will cover the plot command in greater detail.
data("iris") # get the iris data
tbl_df(iris) # get some summary characteristics of the data frame## # A tibble: 150 x 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <fctr>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5.0 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 140 more rowstable(iris$Species, iris$Petal.Width) # create a cross tablulation##
## 0.1 0.2 0.3 0.4 0.5 0.6 1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8
## setosa 5 29 7 7 1 1 0 0 0 0 0 0 0 0 0
## versicolor 0 0 0 0 0 0 7 3 5 13 7 10 3 1 1
## virginica 0 0 0 0 0 0 0 0 0 0 1 2 1 1 11
##
## 1.9 2 2.1 2.2 2.3 2.4 2.5
## setosa 0 0 0 0 0 0 0
## versicolor 0 0 0 0 0 0 0
## virginica 5 6 6 3 8 3 3# scatter plot
# http://www2.warwick.ac.uk/fac/sci/moac/people/students/peter_cock/r/iris_plots/
plot(iris$Petal.Length, iris$Petal.Width, main="Edgar Anderson's Iris Data")
9.1.2 hist() - Histogram
hist(iris$Petal.Width)
9.1.3 barplot() - Bar Plot
sixcyls <- filter(four.six, cyl == 6)
barplot(table(sixcyls$make)) # for categorical data
barplot(table(sixcyls$make), horiz = TRUE)
9.1.4 mosaicplot() - Mosaic Plot
mosaicplot(table(smokerdata))
9.2 ggPlot2 - better vis
9.2.1 ggplot2 Scatter Plot
ggplot(mtcars, aes(x=wt, y=mpg)) +
geom_point(shape = 1) +
geom_smooth(method = lm)
9.2.2 ggplot2 Bar Graph
ggplot(mtcars, aes(x = cyl)) +
geom_bar(stat="bin")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
mutate(mtcars, cyl = factor(cyl, labels = c("four","six","eight"))) %>%
ggplot(aes(x = cyl)) +
geom_bar(stat="count")
9.2.3 ggplot2 Histogram
ggplot(mtcars, aes(x=mpg)) +
geom_histogram(binwidth=1, colour="black", fill="white")
9.2.4 ggplot2 Line graph
ggplot(data=mtcars, aes(x=mpg, y=wt, group=cyl, colour=cyl)) +
geom_line() +
geom_point()
10 Resources
10.1 Exercises
Reinforce your learning with these manual exercises or two-minute video tutorials.
10.2 Online tutorials
- Data Carpentry - Text-based lessons aimed at the research environment and designed for people with no programming experience
- DataCamp.com - This free, interactive, online workshop tool helps you master the basics. It can be hard to fully grok all the atomistic demands of [R]; this workshop will help
- Lynda Online Training - Includes video description. Duke University Users, use the Duke login
- R-bloggers: R tutorials - a cornucopia of useful information on a variety of topics
- rOpenSci
10.3 Solutions to common tasks and problems in analyzing data.
10.3.0.1 Shareable under CC BY-NC-SA license
Data, presentation, and handouts are shareable under CC BY-NC-SA license

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
11 References
The Split-Apply-Combine Strategy for Data Analysis by H Wickham↩
The Hitchhiker’s Guide to the Hadleverse by Adolfo Alvarez↩
Five great charts in 5 lines of R code each by Sharon Machlis↩
First Steps in R by Maite Ceballos (IFCA) & Nicolas Cardiel (UCM)↩
Cross Tablulation by Selby Markham↩
R Tutorial by Kelly Black↩
Plotting the Iris Data by Peter Cock↩