class: center, middle, inverse, title-slide # Web Scraping ## DSVIL 2017 ### John Little ### 2017-04-25 --- class: center, middle background-image: url(https://www.lib.ncsu.edu/sites/default/files/styles/large/public/DSVIL%20Vertical%20Logo_0.jpg) --- ## Today... ### Web Scraping 9:00 am - 11:00 am Web Scraping: Gathering Data from Websites, Parsing HTML & JSON, Orchestrating APIs, and Gathering Twitter Streams (John Little, Duke University) Preexisting and clean data sets such as the General Social Survey (GSS) or Census data are readily available, cover long periods of time, and have well documented codebooks. Meanwhile, researchers increasingly want to gather their own data from websites which provides a different layer of complexity; accessing content from these sources requires different tools and new techniques. In this workshop we will use an open-source data wrangling tool (OpenRefine) to gather and clean data from webpages, and "crawl" whole websites, discuss and use Application Programming Interfaces (API), and give examples of how APIs are used with social media sources such as Twitter. --- ## Outline 1. **Crawl** whole website -- webscraper.io *45 minutes* 2. **Scrape** and **Parse** -- OpenRefine *25 minutes* 3. **Discuss** and use an **API** (Application Programming Interfaces) *15 minutes* 4. **Examples** of **social media** Analysis & APIs -- TAGS *25 minutes* --- background-image: url(http://4.bp.blogspot.com/-XXCVJfR7jeU/Uh022FJuDVI/AAAAAAAADQA/3x5Fep2oJhM/s320/Data_Science_VD.png) [Data Science Core Skills](http://www.datasciencecentral.com/profiles/blogs/data-scientist-core-skills) Mitchel Sanders (2013) --- class: inverse, middle, center # Crawl WebScraper.io in Chrome Browser --- class: softblue ## Crawl .pull-left[ Moving across or through a website in an attempt to gather data from more than one page (URL) ] .pull-right[  ] --- ## Demonstration Congressional Press Releases - Representative Nancy Pelosi’s Press Releases - CONTENT - Structure of the [Press Release subsection](http://pelosi.house.gov/news/press-releases/) of the site - Pagination - Links to each release - Information Content Structure: Web Site & Web Page(s) - TOOL - [Webscraper.io](http://Webscraper.io) tool works inside of Chrome - Tutorials - Documentation - Community - Free - Alternatively, Fee for Service --- background-image: url(images/selector_graph.png) --- class: green ## Now You Try It 1. Download & Install [Webscraper.io](http://Webscraper.io) ; restart your Chrome browser 2. Use one of the following sites - http://pelosi.house.gov/news/press-releases/ - http://butterfield.house.gov/media-center/press-releases - https://walker.house.gov/media-center/press-releases - http://www.donnelly.senate.gov/newsroom/press - https://price.house.gov/press-releases/ (difficult pagination) 3. Follow [Intructions](https://docs.google.com/document/d/17iKQG9JfREEEThz_Qeai5lvv5mYPRsixi0MKbS6aIsM/edit#heading=h.hdqpl186tuyo) 1-8 - Substitute the site you picked from step 2 (above) - (instructions: http://v.gd/webscraping1111 ) --- class: inverse, middle, center # Scrape & Parse OpenRefine using "Fetch URL" & "parseHTML" --- class: softblue .pull-left[ ## Scrape  Using tools to gather data you can see on a webpage ] .pull-right[ ## Parse Analyzing the strings and symbols to reveal only the data you need  ] --- class: softblue ## HTML Hypertext Markup Language ```html <!DOCTYPE html> <html> <!-- created 2010-01-01 --> <head> <title>sample</title> </head> <body> <p>Voluptatem accusantium totam rem aperiam.</p> </body> </html> ``` --- ## URL  - Server sends back marked-up content - HTML - CSS StyleSheets - JavaScript - Browser parses the HTML --- ## OpenRefine (Fetch & Parse) - Scrape - Add column by fetching URL... - Parse - BeautifulSoup Libraries - Refine uses GREL Expressions to transform data - jSoup is a Java library implementation of BeautifulSoup -- a tool for HTML Extraction - Resources - [Step-by-step example](https://libjohn.github.io/openrefine/start.html#api) - Documentation - [OpenRefine’s documentation](https://github.com/OpenRefine/OpenRefine/wiki/StrippingHTML) on HTML Parsing - [jSoup Documentation](http://jsoup.org/cookbook/extracting-data/selector-syntax) - [CSS](http://flukeout.github.io/) --- ## Demonstration -- Process Outline 1. Fetch HTML by URL from Web Server - Edit column > Add column by fetching URL... 2. Parse HTML - Edit column > Add column based on this column - `parseHTML()` - `select("HTML/CSS handle")` - in Chrome: highlight text > right-click > inspect (Chrome Developer Mode) - choose an array element, typically `[0]` - convert element: - `htmlText()` - `htmlAttr("attribute handle")` --- ### Parsing by HTML elements and CSS 1. Edit Column > Add column based on this column - `value.parseHtml().select("div.contentdata")[0].htmlText()` - `value.parseHtml().select("title")[0].htmlText()` ### Parsing by Brute Force 2. Edit Column > Add column based on this column - `value.split("</title>")[0]` - Edit Cells > Transform > `value.split("<title>")[1]` --- class: green ## Now You Try It 1. [Step-by-Step Worksheet](https://docs.google.com/document/d/173DBCKrfXWT2yGlFeGQ-zaCh5TefwxctL1CoTTQTS1Y/): Complete the *fetching* and *brute force* parsing method in steps 1-4 2. Complete the parsing example in Step 5 3. If you're speedy try the various parsing examples in step 6 - HTML Viewer: http://codebeautify.org/htmlviewer/ --- ## Demonstrate -- Part 2 From price-press_releases.csv - `value.parseHtml().select("div.contentdata")[0].select("strong")` - `value.parseHtml().select("div.contentdata")[0].select("strong")[2].htmlText()` - `value.parseHtml().select("div#centerbox")[0].select("a")[3].htmlAttr("href")` - `forEach(value.parseHtml().select("div#centerbox")[0].select("a"),j,j.htmlAttr("href")).join("|||")` --- class: inverse, middle, center # API using OpenRefine & ParseJSON --- class: softblue ## API ### Application Program Interface A set of rules and protocols used to build a software application. In the context of Web Scraping an API is a method used to gather clean data from a website (i.e. data that is not wrapped in HTML, Javascript, bound in HTTP, etc.) - Built for machine-to-machine interactions - Instructions for programs  --- ## Why Use APIs? -- - Get data in BULK - frontier beyond curated datasets - better data structures and eliminates HTML (JSON is easier to parse) - Easier to generate tidy dataframes -- ## Intellectual Property must be considered --- class: softblue ### Client / Server 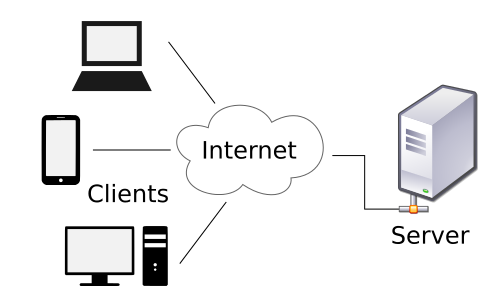 - Same as h2m but now m2m --- ### Simulation... - Person enters a URL  -- - Client & server negotiate handshake (*dramatization...*) -- .right[] --- - Web Browser parses the HTML -- .right[] ??? Ever seen HTML before? --- class: softblue ## JSON * [Javascript Object Notation](https://en.wikipedia.org/wiki/JSON) is a language-independent data format * Currently the most common data data format for asynchronous client/server communication format * Consists of key-value pairs ```json # from https://en.wikipedia.org/wiki/JSON { "firstName": "John", "lastName": "Smith", "isAlive": true, "age": 25, "address": { "streetAddress": "21 2nd Street", "city": "New York", "state": "NY", "postalCode": "10021-3100" }, "phoneNumbers": [ { "type": "home", "number": "212 555-1234" }, { "type": "office", "number": "646 555-4567" }, { "type": "mobile", "number": "123 456-7890" } ], "children": [], "spouse": null } ``` --- ## m2m -- development - Make [OR] interface with the web API - Same as h2m but now m2m *dramatization...* -- .right[] --- ## Demonstration - Demonstration in OpenRefine - http://www.omdbapi.com/?t=rocky&y=&plot=full&r=json - [JSON Viewer](http://jsonviewer.stack.hu/) - `parseJson().imdbID` - Actors - Writer - Title --- class: green ## Now You Try 1. [v.gd/parsing3333](https://docs.google.com/document/d/1ZiHC1v595tf2NAhv4vVdRYy-Ro78Bc37Y0gs1TfGBco/) --- class: inverse, middle, center # Social Media Gather Twitter streams using the TAGS app for Google Sheets --- class: softblue ## TAGS: a tool for collecting Twitter streams - TAGS (“New Sheets”; Version 6.1) - Form driven (not command line) - Minimal setup - Data are collected in Google Sheets - Gather twitter stream data by type - screen-name stream data - screen-name status updates - twitter user favorited tweets - Search term for last 7 days: hashtag stream, username, boolean logic - Limit by date - Schedule to run hourly - set your interval, or run once. - 3 minute setup-video; easy to use - https://youtu.be/Vm0kjAvH5HM - Outputs: raw CSV structured data, plus default social graph visualizations --- background-image: url(images/tags-screen1.png) --- background-image: url(images/gsheets-results1.png) --- background-image: url(images/network-graph.png) --- class: green ## Now You Try... 1. Go to Tags - https://tags.hawksey.info/ 2. Get Tags > Get version 6.1 (requires Google Account) - Make a **copy** of the TAGS 6.1 Template - In the Searchbox search either a hashtag or a Twitter handle - @ViolaDavis - TAGS > Run Now (requires a Twitter Account ; Authorize TAGS) - Wait for results (maybe 60 seconds) 3. Results are found in the "Archive" sheet --- ## Analysis TAGS offers - Summary Sheet - Dashboard Sheet - TAGS Explorer - Network graphs - Top Tweets - Top Hashtags - Top Conversations - Sheet must be publicly available - TAGS Archive - Search filters of the archive --- class: green ## Now You Try... Using your Twitter stream archive and TAGS, visualize the network of a twitter user 1. TAGS > Add Summary Sheet 2. TAGS > Add Dashboard Sheet 3. Make your Google Sheet Public - Share button > Done - <img src="images/Google-Share-button.png" style="vertical-align: top;"> 4. On the *Readme/Settings* Sheet > TAGSExplorer --- ## Historical Twitter Data - Last 7 Days from the Twitter API - [gnip.com](http://gnip.com) for historical data - **Plan Ahead** --- ## Other Analysis Tools ### Simple - Netylics - https://netlytic.org/ - SocioViz - http://socioviz.net/ ### Visual Text Analysis - Voyant - http://voyant-tools.org/ - Overview - https://www.overviewdocs.com/ ### Network Graph Analysis - Gephi - https://gephi.org/ --- background-image: url(images/keys6a.jpg) ## API Keys .left-column[ - You can - Regenerate keys - Change access permissions - Delete the keys/application - Keep your *Secret Key* a secret! ] .right-column.pull-right[ - A way for the Service Host to know how their API is being used - Register your Application at the Twitter API Dashboard ] <!-- Image credit: http://www.publicdomainpictures.net/view-image.php?image=167489 --> --- ## Where are my Keys? 1. http://apps.twitter.com - Name = TAGS Twitter Data (must be unique across Twittersphere) - Description = My TAGS application collects my Twitter Searches - Web Site = A page that connects to you, or better to your application (e.g. A results report) - Callback URL = https://script.google.com/macros/ - Read the developer rules and accept the terms 2. Get your keys - Click on the *Keys and Access Tokens* Tab - Consumer Key (API Key) - Consumer Secret (API Secret) --- ## More on Twitter - Easy Tools: [Twitter & APIs](https://libjohn.github.io/twitter-gather/) | [video](http://library.capture.duke.edu/Panopto/Pages/Viewer.aspx?id=82e1fe62-a003-4160-871e-765e027fc1b0) - Great Analysis Tools: [with R](https://libjohn.github.io/rtweet/slides.html) | [video](https://warpwire.duke.edu/w/iZ4BAA/) --- ## Thank You For Attending .pull-left[ ### I am ... - **John Little** - http://libjohn.github.io - http://github.com/libjohn #### Schedule Me - [http://v.gd/littleconsult](http://duke.libcal.com/appointment/2695) ] .pull-right[ ### Duke Univesrity... - **Data & Visualization Services** - http://library.duke.edu/data - The /Edge, Bostock (1st Floor) #### Walk-in Hours - [Schedule](http://library.duke.edu/data/about/schedule) #### Our Workshops - [Current Workshops](http://library.duke.edu/data/news) - [Past Workshops](http://library.duke.edu/data/news/past-workshops) #### Contact Us - askData@Duke.edu ] --- ## Resources The following text will support the Web Scraping / Twitter stream gathering workshop - [Web Scraping](https://docs.google.com/presentation/d/1QVUR3B4QDgM5fLBtFditwKyGwij0hM1qDCUL56vs34k/edit#slide=id.p) - [docs.google.com/presentation/.../](https://docs.google.com/presentation/d/1QVUR3B4QDgM5fLBtFditwKyGwij0hM1qDCUL56vs34k/edit#slide=id.p) - The [OpenRefine Workbook](https://libjohn.github.io/openrefine/) - https://libjohn.github.io/openrefine/ - [Twitter Stream Gathering](https://libjohn.github.io/twitter-gather/slides.html) - https://libjohn.github.io/twitter-gather/slides.html - [Regular Expressions](https://libjohn.github.io/regex/slides/) - https://libjohn.github.io/regex/slides/ --- ## Image Credits - [Sloth](https://www.flickr.com/photos/ndanger/4425407800/in/photolist-aHctY-7K4nyu-5GWYyx-bwwbvt-bwwe7r-bwwbNr-S8zN-bwwekD-S8AM-dXgyC-bwwdkM-nJsop-B6SZ-bwwcaF-bwweB6-bwwcw6-bwwdtv-bwwaUx-bwwcUD-bwwcMn-bwwbdt-bwwdci-4wQdR-5jWS4P-xR5Wd-aZ1zL2-2kbBbL-s2hYyV-qYyRTS-9SDuok-62grYS-9Y8DY3-bvMPWn-bvV6wK-7Sxoah-Lwv5Z-8Znq63-6zatgS-cTR7h-oqwqZ-ziEuE-38Fp1D-7yAuKp-oQejEx-iJyMWk-dbJrj-a7K52r-f4rdX-4TJtNh-8F73H6) by [Dave Gingrich](https://www.flickr.com/photos/ndanger/) - [Scraping Propolis](https://commons.wikimedia.org/wiki/File:Scraping_propolis.jpg) by [fishermansdaughter](https://www.flickr.com/photos/fishermansdaughter/) - [URL](https://commons.wikimedia.org/wiki/File:Uniform_Resource_Locator_%28URL%29_example.PNG) - [API schematic](https://moz.com/blog/apis-for-datadriven-marketers) - [Client / Server](https://commons.wikimedia.org/wiki/File:Client-server-model.svg) - [Good human handshake](http://giphy.com/gifs/thomas-U2XboRuN89Idi) - [happy parsed dance](http://giphy.com/gifs/80s-1980s-thomas-dolby-wCKmBd7oNtA4g) --- class: center, middle ## Shareable under CC BY-NC license Data, presentation, and handouts are shareable under [CC BY-NC license](https://creativecommons.org/licenses/by-nc/4.0/) 